
All Activity
- Today
-
I went into the power settings and disabled USB selective suspend. I also made sure the system wouldn't turn off any disks. I just did this, so it'll take a little time to see if it had any results. I actually had no idea the Sabrent had flashable firmware. I downloaded and applied the one linked in that thread. Again, I just did this a few hours ago, so results (if any) may take a day or two to manifest. Thanks for the link! However, after flashing, I did try to do another chkdsk /b on the Exos, but it did the same thing and got jammed at 5%. I'm doing a "clean all" on it now, but if I'm reading things right, that'll take awhile, so I'll leave it overnight. I'm beginning to think the PSU for the Sabrent might be underpowered, as others in that forum also complained about disk drops, especially when it came to SSDs. I have all 10 bays populated with various Seagate and WD spinners, which could be causing issues. If the flash and power settings don't improve things, I'm thinking of ditching it for a 6-bay Terramaster: https://www.amazon.com/gp/product/B0BZHSK29B/ref=ox_sc_act_title_1?smid=A307CH216CTGMP&psc=1 I don't like the fact that the Terra seems to use old-school drive sleds, but I'll gladly accept that hassle if it means I can get the pool back to 100% (I can settle for only six disks in the meantime). I might even take apart the Sabrent to see if the PSU can be upgraded (probably not, but it's worth looking into). More to come!
- Yesterday
-
I have a drivepool with 10 drives set up as drive Y: Everything in Y: is set to 2X real-time duplication. Is there any way, by using the balancing settings, hierarchical pools etc, to set only one specific folder (and its sub-folders) in Y: to NOT use real-time duplication? I don't want to make a new drive letter if I don't have to. The problem i'm having is with drive image backup software such as Hasleo, Macrium Reflect, etc. They often make HUGE files (100GB and up) and I'm finding that I often get messages such as this: ================================================================================== Duplication Warnings There were problems checking, duplicating or cleaning up one or more files on the pool. You can have DrivePool automatically delete the older file part in order to resolve this conflict. One or more duplicated files have mismatching file parts. One reason why this can happen is if something changed the duplicated file's parts directly on the pooled disk and not through the pool. This can also happen if a disk was altered while it was missing from the pool. You can resolve the conflicts manually by deleting the incorrect file part from the pooled disks. Files: \Pool2\Backup\SYSTEM_Backups\JR4_backups\JR4_RDI\JR4_C_NVME__D_SSD_20240409220013_224_4.rdr File parts different. \Pool2\Backup\SYSTEM_Backups\JR4_backups\JR4_RDI\JR4_C_NVME__D_SSD_20240409220013_224_2.rdr File parts different. \Pool2\Backup\SYSTEM_Backups\JR4_backups\JR4_RDI\JR4_C_NVME__D_SSD_20240409220013_224_3.rdr File parts different. ===================================================================================== Since there's no easy way to know what size the completed backup file is going to be, I figure it's best to let Drivepool wait until the entire large file is completed before duplication begins. Is there a simple way to accomplish this without setting up new drive letters, network file shares, etc?
-
I'm sure you figured it out already... From the images you posted, it just looks like a simple change is needed. The pool called ORICO BOX is fine as is. The one in the first image is not correct. You should have: A pool that has 12TB1 & 12TB2 with NO duplication set. (lets give it drive letter W:) A pool called ORICO BOX with NO duplication set. (with the assorted drives) (Lets call it drive letter X:) Now, drive W: essentially has 24TB of storage since anything written to W: will only be saved to ONE of the two drives. You can set the balancing plugin to make them fill up equally with new data. Drive X: essentially has 28TB of storage since anything written to X: will only be saved to ONE of the five drives. At this point, you make ANOTHER new pool, Lets call it Z: In it, put Drivepool W: and Drivepool X:. Set the duplication settings to 2X for the entire pool. Remember, you are only setting Drivepool Z: to 2X duplication, no other drivepools need changed. What this should do (if I didn't make a dumb typo): Any file written to drive Z: will have one copy stored on either 12TB1 OR 12TB2, AND a duplicate copy will be stored on ONE of the five Orico Box drives. You must read & write your files on drive Z: to make this magic happen. Draw it out as a flowchart on paper and it is much easier to visualise.
-
 MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
 MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
MrPapaya reacted to an answer to a question:
Beware of DrivePool corruption / data leakage / file deletion / performance degradation scenarios Windows 10/11
-
Pseudorandom thought, could it be something to do with USB power management? E.g. something going into an idle state while you're AFK thus dropping out the Sabrent momentarily? Also it looks like Sabrent has a support forum, perhaps you could contact them there? There's apparently a 01-2024 firmware update available for that model that gets linked by Sabrent staff in a thread involving random disconnects, but is not listed in the main Sabrent site (that I can find, anyway).
-
I've resisted saying this, but I think there's a problem with the Sabrent. Which, if true, really screws me. I'm beginning to suspect the Sabrent because I tried long formatting a brand-new 18 TB Exos and it also failed. I started the process in disk management, made sure that the percentage was iterating, and went to bed. Got up and nothing was happening and the disk was still showing "raw". So, at some point, the format failed without even generating an error message. I'll also periodically wake up to a disk or two having randomly dropped-out of the pool. I'll reboot the machine and those same disks will magically (re)appear. I'm currently doing a chkdsk /b on the new Exos after doing a quick format in order to assign it a drive letter (which worked). It started-out fine, but is now running at less than a snail's pace, with chkdsk reporting that it won't complete for another 125 hours. Scratch that, now chkdsk is saying 130 hours and it has stubbornly stayed at 5% for the past two hours. I do have another machine I can try long formats on and will do so, but I'm not sure what that'll prove at this point. I've also tried consulting Event Viewer, but so much data gets dumped into it that I can't really pinpoint anything (maybe that's just me being an idiot). I was really, REALLY relying on something like the Sabrent since it seemed to be a Jack-of-all-trades solution to having a bunch a disks without resorting to a server-style case or expensive NAS. If anyone has any suggestions as to a similar device, I'd love to hear it.
- Last week
-
Also, the system Event Viewer can give you an indication for why it failed. In fact, with support tickets, it's one of my first go-tos for troubleshooting weird issues. If you're seeing a lot of disk errors or the like in the event viewer, it can indicate an issue. Also, the burst test in StableBit Scanner can help identify communication issues with the drive.
-

My NVME Samsung 980 Pro 500gb reported as Damaged, what should I do?
Christopher (Drashna) replied to SaintTDI's question in General
welcome! -
Unknown Unallocated 2TB disk after replacing two drives. (Updated)
Christopher (Drashna) replied to Tiemmothi's question in Nuts & Bolts
That is the pool drive. The 2048GB size exactly, that is the giveaway, and the "COVECUBECoveFsDisk_____" is just confirmation of that. (that's the driver name). I'm not sure why that happened, but uninstalling and reinstalling StableBit DrivePool can also fix this. And the drive is always reported as that size, in that section of Disk Management. But elsewhere it shows the correct size. -
I appreciate this thread. 4tb unusable for duplication and I was looking for an answer and reading through the thread you guys answered about 4 more questions. I guess I'm reviving the conversation by replying. But thanks.
-
When you say chkdsk, was that a basic chkdsk or a chkdsk /b (performs bad sector testing)? I think I'd try - on a different machine - cleaning (using the CLEAN ALL feature of command line DISKPART), reinitialising (disk management) and long formatting (using command line FORMAT) it to see whether the problem is the drive or the original machine. If I didn't have a different machine, I'd still try just in case CLEAN ALL got rid of something screwy in the existing partition structure. I'd then run disk-filltest (a third party util) or similar on it to see if that shows any issues. If it passes both, I'd call it good. If it can only be quick-formatted, but passes disk-filltest, I'd still call it okay for anything I didn't care strongly about (because backups, duplications, apathy, whatever). If it fails both, it's RMA time (or just binning it). YMMV, IMO, etc. Hope this helps!
-
What do you guys think about a drive that fails a long format (for unknown reasons), but passes all of Scanner's tests, isn't throwing out SMART errors, and comes up fine when running chkdsk?
-
Ok! Thank you very much
-

Unknown Unallocated 2TB disk after replacing two drives. (Updated)
Tiemmothi posted a question in Nuts & Bolts
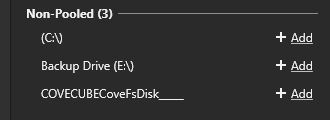
I recently replaced two 4tb drives that were starting to fail with two 8tb drives. I replaced them one a time over a span of 4 days. The first drive replacement was flawless. The second drive I found an unallocated 2048.00GB Disk 6 (screenshot 1). When looking at it via Drive pool's interface it shows up as a COVECUBEcoveFsDisk__ (Picture 2). Windows wants to initialize it. I don't want to lose data. But I'm not entirely sure what's going on. Any insight or instructions on how to fix it? Thank you. *Update. My Drivepool is only 21.8TB large so i think it is missing some space. Forgive the simple math. 8+8+4+4 is about 24tb and im showing a drivepool of 21.8tb. Thats about what my unallocated space is give or take. *New Update. After a few (more than 2) for windows updates and stuff and letting it balance and duplicate it resolved itself.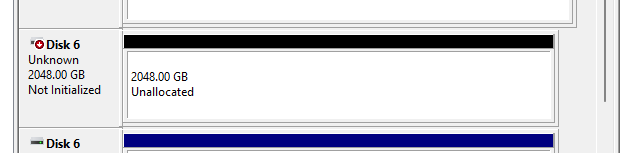
-
Tiemmothi joined the community
-
Sorry, I didn't mention: Upload verification was disabled. I opened a ticket.
- Earlier
-
 If that's 100GB (gigabytes) a day then you'd only get about another 3TB done by the deadline (100gb - gigabits - would be much worse), so unless you can obtain your own API key to finish the other 4TB post-deadline (and hopefully Google doesn't do anything to break the API during that time), that won't be enough to finish before May 15th. So with no way to discern empty chunks I'd second Christopher's recommendation to instead begin manually downloading the cloud drive's folder now (I'd also be curious to know what download rate you get for that).
If that's 100GB (gigabytes) a day then you'd only get about another 3TB done by the deadline (100gb - gigabits - would be much worse), so unless you can obtain your own API key to finish the other 4TB post-deadline (and hopefully Google doesn't do anything to break the API during that time), that won't be enough to finish before May 15th. So with no way to discern empty chunks I'd second Christopher's recommendation to instead begin manually downloading the cloud drive's folder now (I'd also be curious to know what download rate you get for that). -
 I have been using robocopy with move, over write. it 'deletes' the file from the cloud drive. its not shown any longer, and the 'space' is shown to be free. the mapping is being done to some degree, even as a read only path. if there were some way to scan the google drive path and 'blank' as in, bad map locally in the BAM map that would force a deletion of the relevant files from the google path. this would do wonders. glasswire reads that I'm getting about 2mb down. this is no where near the maximum, but it looks like I get about 100gb a day.
I have been using robocopy with move, over write. it 'deletes' the file from the cloud drive. its not shown any longer, and the 'space' is shown to be free. the mapping is being done to some degree, even as a read only path. if there were some way to scan the google drive path and 'blank' as in, bad map locally in the BAM map that would force a deletion of the relevant files from the google path. this would do wonders. glasswire reads that I'm getting about 2mb down. this is no where near the maximum, but it looks like I get about 100gb a day. -
My NVME Samsung 980 Pro 500gb reported as Damaged, what should I do?
Christopher (Drashna) replied to SaintTDI's question in General
That's a hard question to answer. SSDs tend to be fast, including in how they fail. But given this, I suspect that you might have some time. However, back up the drive, for sure! Even if you can't restore/clone the drive, you'd be able to recover settings and such from it. But ideally, you could restore from it. And cloning the drive should be fine. Most everything is SSD aware anymore, so shouldn't be an issue. But also, sometimes a clean install is nice. -
Would you mind opening a ticket about this? https://stablebit.com/contact/ This is definitely diving into the more technical aspects of the software, and I'm not as comfortable with how well I understand it, and would prefer to point Alex, the developer, to this discussion directly. However, I think that some of the "twice" is part of the upload verification process, which can be changed/disabled. Also, the file system has duplicate blocks enabled for the storage, for extra redundancy in case of provider issues (*cough* google drive *cough*). But it also sounds like this may not be related to that.
-
This is mainly an informational post. This is concerning Windows 10. I have 13 drives pooled and i have every power management function set so as to not allow Windows to control power or in any way shut down the drives or anything else. I do not allow anything on my server to sleep either. I received a security update from Windows about 5 days ago. After the update I began daily to receive notices that my drives were disconnected. Shortly after any of those notices (within 2 minutes) I received a notice that all drives have been reconnected. There was never any errors resulting from whatever triggered the notices. I decided to check and I found that one of my USB controllers had its power control status changed. I changed it back to not allowing Windows to control its power and I have not received any notices since. I do not know for sure but I am 99% sure that the Windows update toggled that one controller's power control status to allow windows to turn it off when not being used. I cannot be 100% sure that I have had it always turned off but, until the update, I received none of the notices I started receiving after the update. I suggest, if anyone starts receiving weird notices about several drives becoming lost from the pool, that you check the power management status of your drives. Sometimes Windows updates are just not able to resist changing things. They also introduce gremlins. You just have to be careful to not feed them after midnight and under no circumstances should you get an infested computer wet.
-
Make sure that you're on the latest release version. There are some changes to better handle when the provider is read only (should be at least version 1.2.5.1670). As for the empty chunks, there isn't really a way to discern that, unfortunately. If you have the space, the best bet is to download the entire directory from Google Drive, and convert the data/drive, and then move the data out.
-
I'm not aware of a way to manually discern+delete "empty" CD chunk files. @Christopher (Drashna) is that possible without compromising the ability to continue using a (read-only) cloud drive? Would it prevent later converting the cloud drive to local storage? I take it there's something (download speeds? a quick calc suggests 7TB over 30 days would need an average of 22 Mbps, but that's not including overhead) preventing you from finishing copying the remaining uncopied 7TB on the cloud drive to local storage before the May 15th deadline?
-
I need some assistance, fast. about a year ago, google changed their storage policy. I had exceeded what was then the unlimited storage by about 12 tb. I immediately started evacuating it. I only got it down 10 gig from 16, and google suspended me with read only mode. it can delete, but it cannot write. I have continued to download the drive. it is now down to about 7 tb so far as the pool drive is concerned, but unless drive pool has a mode to 'bad map' and delete the sector files from the drive pool, I am still at 12 tb and way over its capacity. I do appreciate that cloud drive is discontinuing google drive, but I still have some time, but I need to delete as much from the google path as possible, and I can't do that without being able to write back to it, which I cannot do. 'delete bad/read only but empty' would be a big help.
-
 bobil joined the community
bobil joined the community -
Thanks, fortunately no issues once all drive scans completed...but it took a while. Potential related question - and I can post a new ticket if you prefer: If I upgrade my server to W11 from W10 - anything I need to be concerned about re: Drivepool/Scanner? I'm assuming all should migrate over w/o any other work required? I also just noticed there are new versions for both (see screenshot). Haven't updated in ages, but looks like I can just follow the "click here" prompts to update? Should I shut down the software first?
-
Hi, isn't there some priorization taking place under the hood when deciding about which chunk to upload first? I just did few experiments with Google Cloud Storage and 100 MB chunk size, cache size 1 GB (initially empty except pinned metadata and folders), no prefetch, latest public CloudDrive: a) pause upload b) copy a 280 MB file to the cloud drive c) resume upload With this sequence, the whole plan of actions seems to be well defined before the actual transfer starts. So lot's of opportunity for CloudDrive for batching, queueing in order etc. Observing the "Technical Details" window for the latest try, the actual provider I/O (in this order) was: Chunk 3x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 72 MB Chunk 3x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 72 MB Chunk 4x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 80 MB Chunk 10x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 4 kb, + 3 "WholeChunkIoPartialSharedWaitForRead" with few kb (4 kb, 4 kb, 8 kb) Chunk 10x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 4 kb, + 3 "WholeChunkIoPartialSharedWaitForCompletion" with few kb (4 kb, 4 kb, 8 kb) Chunk 0x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 4 kb Chunk 0x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 4 kb Chunk 4x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 23 MB Chunk 4x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 23 MB Chunk 5x1 Write 100MB, length 100 MB Chunk 6x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 11 MB Chunk 10x1 Read 100MB because: "WholeChunkIoPartialMasterRead", length 16 kb, + 4 "WholeChunkIoPartialSharedWaitForRead" with few kb (4 kb, 4 kb, 4 kb, 12 kb) Chunk 10x1 Write 100MB because: "WholeChunkIoPartialMasterWrite", length 16 kb, + 4 "WholeChunkIoPartialSharedWaitForCompletion" with few kb (4 kb, 4 kb, 4 kb, 12 kb) So my questions / suggestions / hints to things that shouldn't happen (?) in my opinion: The chunk 10x1 is obviously just for filesystem metadata or something; it's few kb, for which a chunk of 100 MB has to be downloaded and uploaded - so far so unavoidable (as described in here). Now the elephant in the room: Why is it downloaded and uploaded TWICE? The whole copy operation and all changes were clear from the beginning of the transmission (that's what I paused the upload for until copying completely finished). Ok, may be Windows thought to write some desktop.ini or stuff while CloudDrive was doing the work. But then why did it have to be read again and wasn't in the cache on the second read? Caching was enabled with enough space, also metadata pinning was enabled, so shouldn't it then be one of the first chunks to cache?. Why is chunk 4x1 uploaded TWICE (2 x 100MB) with 80 MB productive data the first time and 20 MB the second?! Isn't this an obviuous candidate for batching? If chunk 5x1 is known to be fully new data (100 MB actual WORTH of upload), why does it come after 3x1, 4x1 and 10x1, which were all only "partial" writes that needed the full chunk to be downloaded first, only to write the full chunk back with only a fraction of it actually being new data. Wouldn't it be more efficient to upload completely new chunks first? Especially the filessystem chunks (10x1 and 0x1 I'm looking at you) are very likely to change *very* often; so prioritizing them (with 2x99 MB wasted transfered bytes) over 100 MB of actual new data (e.g. in chunk 5x1) seems a bad decision for finishing the job fast, doesn't it? Also, each upload triggers a new file version of 100 MB at e.g. Google Cloud Storage, which get's billed (storage, early deletion charges, ops...) without any actual benefit for me. So regarding network use (which is billed by cloud providers!): Naive point of view: I want to upload 280 MB of productive data Justified because of chunking etc.: 300 MB download (partial chunks 0x1, 3x1, 10x1) + 600 MB upload (4x1, 5x1, 6x1, 0x1, 3x1, 10x1) Actually transfered in the end: 500 MB download + 800 MB upload. That's 66% resp. 33% more than needed?
-
Wouldn't it be more efficient to just load the parts of the chunk that were not modified by the user, instead of the whole chunk? One could on average save half the downloaded volume, if I'm correct. Egress is expensive with cloud providers. 😅 Think: I modify the first 50 MB of a 100 MB chunk. Why is the whole 100 MB chunk downloaded just to overwrite (= throw away) the first 50 MB after downloading?





