JazzMan
-
Posts
72 -
Joined
-
Last visited
-
Days Won
2
JazzMan's Achievements
-
 JazzMan reacted to an answer to a question:
Commandline copy poltergeists.
JazzMan reacted to an answer to a question:
Commandline copy poltergeists.
-
JazzMan reacted to an answer to a question:
Added a drive to the DrivePool but it is never used?
-
Unless it's somewhat reproducible, this may be hard to track down, but doesn't necessarily seem like a DP issue. You could post some additional information about your configuration, but I'm not sure that would help either. Specific crucial product? Windows version? PC RAM? page file settings? How often are you maxing out the system when this happens? (CPU, RAM, background tasks, etc). You could also run something like CrystalDiskInfo to check the health of the SSDs. How is DP configured (No duplication, 2x duplication, etc.)? Are these SSDs just data or do they also have the OS/boot partition? The only time I've seen my system sluggish to open a file from SSD is due to a known issue in Office 2013. This doesn't sound like your problem as your example is media files.
-
I can be corrected, but I don't think Scanner performs the same functions as Chkdsk. My understanding is Scanner is monitoring SMART data and exercising the drives to prevent bit rot. Chkdsk is intended to ensure that the various metadata and such of a file system (NTFS in this case) are all complete and consistent. The former is more of a hardware level operation, the latter more of an OS level operation. These days, chkdsk errors are more the result of programs crashing while writing to the disk than of issues with the physical media. It sounds lie you got past the error you posted about, although your post seems to imply you've been having other issues or frustrations with your setup. My two cents; (Assuming you don't have drive letters for each of the 10 drives) Create a folder on your C: drive and in it create NTFS mount points for each of the 10 individual drives. That way you can then easily see the contents of an individual drive or chkdsk the mount point. Create a *.bat script to chkdsk the 10 drives. Re-consider the DAS solution, especially before buying a second enclosure I don't know your use case, but having a JBOD enclosure hanging off a computer by USB/USBC/eSATA is always going to be less performant than having drives connected to internal SATA ports, and is also going to be more prone to drives dropping out under any sort of load. Without duplication, and with only one enclosure, you have also not mentioned what your backup strategy is. If you are tech savvy enough, I'd really recommend building a separate NAS computer, running DP on that, and serving up the files you need over the LAN. I've used Norco ITX-S8 cases in the past, but they're out of business now. It looks like Jonsbro makes cases with backplanes for NAS builds. Mostly they max out at 8x usually. I'm not sure if anyone makes 10x ones. You might have to get some larger drives or build in a non-backplane (non hot-swap) case for that.
-
The pool is a collection of NTFS drives, but the file system the pool driver presents to windows isn't 100% NTFS. It's close, but there a few things native NTFS can do that the driver can't. Even if it says "NTFS" if you do a "Properties" on the pool's drive letter, behind the scenes it is technically "CoveFS" or something. This is why chkdsk isn't working. That isn't a problem. You can't CHKDSK the pool. The driver doesn't support that. You would CHKDSK the drives in the pool individually.
-
The only other two things I can think of are not correctly putting quotes around [destination] if it has spaces, and some issue with the ACL (permissions) getting borked on some file(s) in the source. If you are in CMD and type your; copy * [destination] that gives the error, what then happens if you do a; dir [destination] Also, what happens if you do; copy *.* [destination] instead of just the single asterisk? Another thing you could try is mounting each drive in the pool as a separate drive letter or mountpoint and going through them one at a time with the copy command to see which disk "behind the scenes" is giving the error. I don't think it's a disk corruption or DP issue though from what you've said, especially if there isn't duplication. I think it's something about the way you are using the copy command.
-
Thanks. I checked that service log but I don't see any errors. I think the problem is not necessarily DP's fault. If I look at Disk Administrator none of the drives for the pool are shown there. So I guess something in the BIOS or HBA isn't correctly resetting the drives on a Windows restart? As I say, I can do a full power shutdown and turn on and the drives and system come back up fine.
-
Is the pool healthy? Is it using duplication? does chkdsk'ing the individual drives in the pool show any errors? Are there any hidden files you're trying to copy? Are there any extremely long paths/filenames or unicode characters involved? I get very sporadic errors like this if duplicated files are mismatched or before some error that a chkdsk /f fixes. I don't know exactly why copy would behave differently than xcopy or powershell, but I'm sure the code is different, so edge cases are being handled differently.
-
JazzMan reacted to an answer to a question:
Pool not coming back online after reboot
-
Currently running DP 2.3.3.1505 on a Win 10 x64 22H2 NAS server system with an Intel Z370 chipset. Power ioptions are set to never sleep and hibernation is disabled. The advanced power settings say to turn off the hard disk after 20 minutes. The boot drive is an SSD and there are 8 HDDs as a mixture of Seagate Ironwolf, WD Red and WD Green drives. When I "Shut down" the system normally from the Start menu, and then turn it back on with the power butten all is ok. When I select "Restart" from the start menu, when the system restarts the pool drive is unavailable. The computer is mostly managed remotely via VNC, etc, so a trip to the computer room is not ideal for every reboot. This particular configuration is a bit of a new build, so I'm not sure if it was working and something changed or it never worked right. However, I've had this pool of drives in other systems/motherboards like a Z170 and Z77 without this symptom. I've also been a DP user for 10 years or so with multiple keys and installs. Thoughts?
-
JazzMan reacted to an answer to a question:
n00b; SMART Unstable Sector
-
I got this resolved, but not using chkdsk. "chkdsk /r" got to about 95% complete and the computer did a BSOD style hard reboot. The SMART warning was still there. Instead, referring to this info about this SMART warning; https://harddrivegeek.com/current-pending-sector-count/ I removed the drive from the pool and formatted it with all zeroes. That process brought the Current Pending Sector Count back to 0 and did not increase the Reallocated Sectors Count or Reallocation Event Count, which are also still both zero. I don't know how frequently the Scanner information gets refreshed, but the message seemed to disappear sometime after the drive was 95% formatted. Although I'll continue to monitor the drive, for now I think this was more of a "false positive" warning than a true disk failure portent. If Scanner, Format, etc work from outer tracks to inner tracks, it seems like the offending sector was near the inner part of the disk and the warning would have stayed around for a long time until the drive got 95%+ full. It's unfortunate I had to evacuate the disk to do the format, then go through the rebalancing after adding the zeroed disk back, but because of the BSOD, I can't confirm if "chkdsk /r" would have fixed this or not. Because the drive apparently did not need to reallocate the sector, I'm having a hard time imagining the BSOD at about 95% and chkdsk hitting the potentially bad sector are related, but I didn't want to run it again to find out.
-
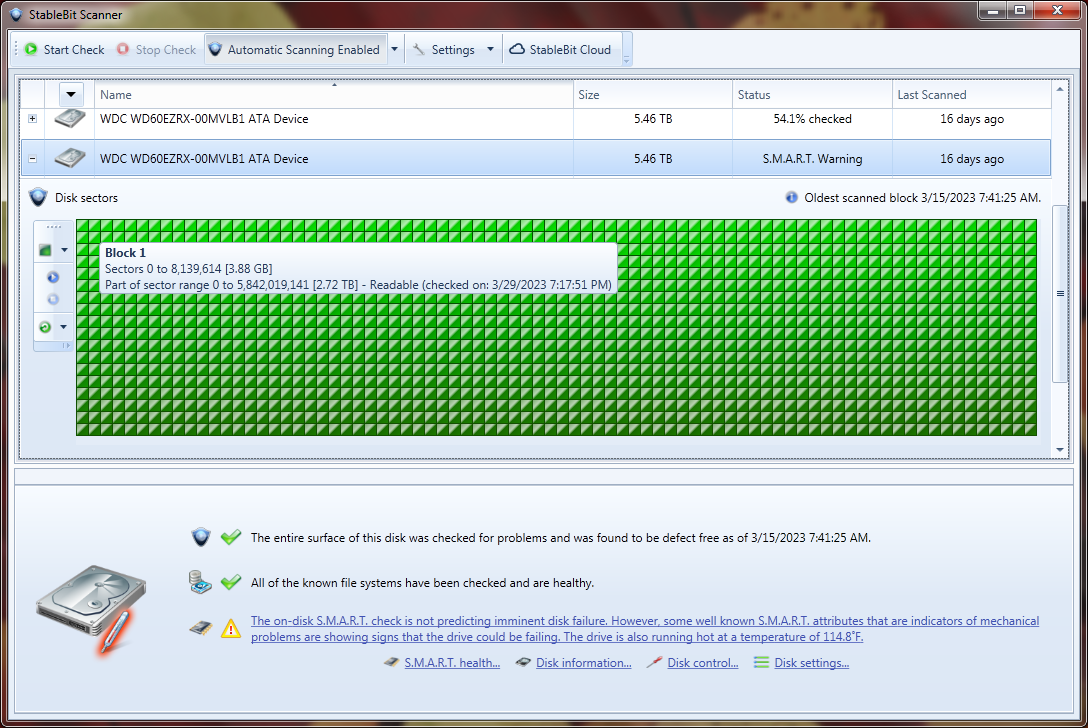
I let the scan complete and still have the SMART error about this sector. I guess I';; have to try the chkdsk.
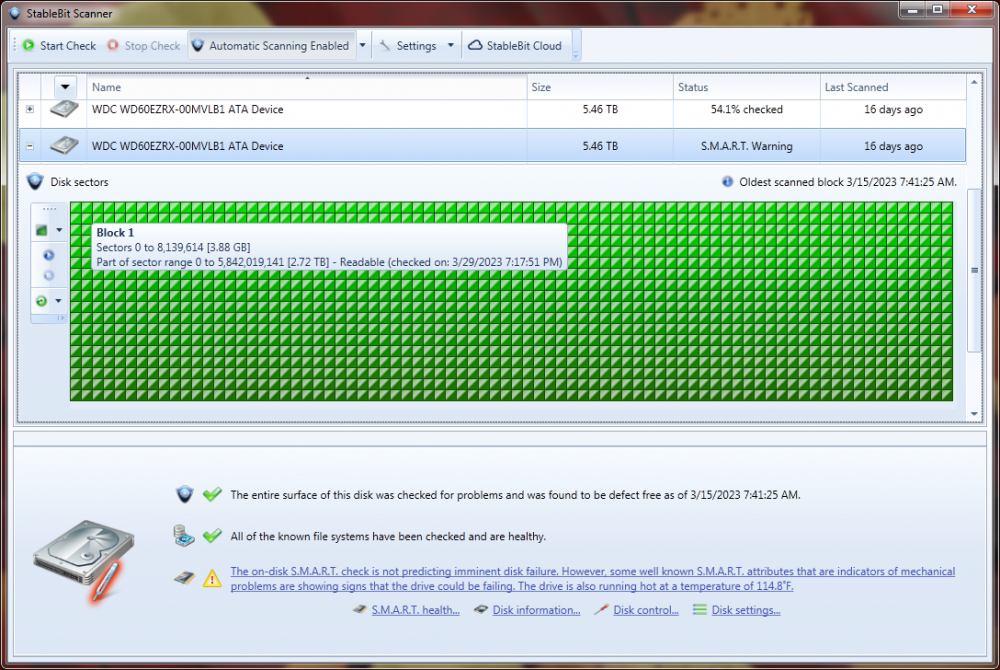
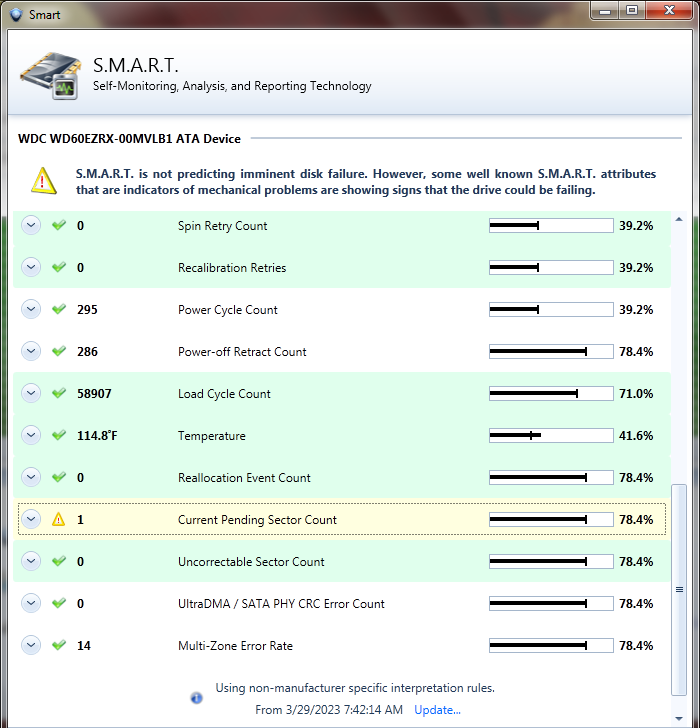
-
Thanks, I'll proceed with this info. I find some of the UI confusing.
-
JazzMan reacted to an answer to a question:
n00b; SMART Unstable Sector
-
I'm getting the following error: 1 Current Unstable Sector Count "There is currently 1 unstable sector on the hard disk. An unstable sector is a sector that can't be read. The drive will automatically swap the bad sector for a good one whenever new data is written to it, however, the original data may be lost." How can I either force a write to the sector for the drive to make up its mind to mark it bad, or force the drive to mark it bad even if its good so I don't keep getting this warning for this sector? I assume the scanning process doesn't "fix" this? Is there an easy way to run a scan on just one disk?
-
I didn't name a brand, but the MediaSonic was the USB 3.0 JBOD I was having trouble with. I got rid of that and built a small ITX PC with internal drives. That was about 5 years ago. I agree eSATA was more stable, but isn't an option in my current setup. I don't have any experience with Thunderbolt (JBOD or otherwise) so was looking for some input in that area. Glad your USB 3.x setup is working for you.
-
Can anyone comment on how well DP would work with a Win 10 laptop and a 4 bay TB3 JBOD? I've used DP for quie a while, but had most success with internal drives. I did have an external USB 3.0 JBOD some years ago but it was rather flaky, often dropping the pool under sustained load (say copying a few hundred MB in one operation), which would then (as I remember) lead to needing to reboot the computer (I don't think re-plugging the USB cable or power cycling the JBOD was usually enough) and DP wanting to rescan the pool before I could use it again. I blamed that mostly on the JBOD hardware/firmware though, and not DP. Will TB3 provide a more stable pool, or am I likely to face similar issues?
-
Sorry, I haven't been working on that system in a while. When I left it it was still a sporadic issue. I never got to the bottom of why the system would hang, nor why when that happened DP felt it needed to re-scan all 150TB. I would suggest you collect the logs Chris asks for above and submit a support ticket specific to your situation.
-
.I don't normally keep a keyboard connected to that server and access it through VNC. I'm still trying to get a dump from when this happens.